在當今數(shù)據(jù)爆炸的時代,企業(yè)每天需要處理的數(shù)據(jù)量已經(jīng)從GB級躍升至TB甚至PB級。如何高效、可靠地處理這些海量數(shù)據(jù),成為技術(shù)領(lǐng)域的一個核心挑戰(zhàn)。從單機的并發(fā)編程到跨機器的分布式系統(tǒng),數(shù)據(jù)處理技術(shù)經(jīng)歷了一場深刻的演進,每一次躍遷都是為了突破性能、可靠性與擴展性的極限。
并發(fā)編程:榨干單機性能的利器
當數(shù)據(jù)量尚未達到“海量”級別,或者業(yè)務對實時性要求極高時,充分利用單臺服務器的計算資源是最直接的選擇。并發(fā)編程正是在這種背景下成為關(guān)鍵技術(shù)。通過多線程、多進程或異步I/O等模型,程序可以同時執(zhí)行多個任務,從而顯著提高CPU利用率和系統(tǒng)吞吐量。
例如,一個網(wǎng)絡(luò)服務器使用線程池處理并發(fā)的用戶請求;一個數(shù)據(jù)分析腳本使用多進程并行處理多個文件。Java的并發(fā)包(java.util.concurrent)、Python的asyncio庫、Go語言的goroutine都是這一領(lǐng)域的杰出代表。它們幫助開發(fā)者在單機環(huán)境下,構(gòu)建出高響應、高吞吐的數(shù)據(jù)處理管道。
并發(fā)編程有其物理上限。單臺服務器的CPU核心數(shù)、內(nèi)存容量和磁盤I/O終究是有限的。當數(shù)據(jù)量增長到單機無法在可接受時間內(nèi)處理完畢時,技術(shù)的焦點便從“縱向擴展”(增強單機能力)轉(zhuǎn)向了“橫向擴展”(增加機器數(shù)量)。
分布式系統(tǒng):橫向擴展的藝術(shù)
分布式系統(tǒng)的核心思想是將一個龐大的計算任務或海量數(shù)據(jù)集,分解成多個子任務或數(shù)據(jù)分片,并將其分發(fā)到由網(wǎng)絡(luò)連接的多臺計算機(節(jié)點)上并行執(zhí)行,最后將結(jié)果匯總。這解決了單機在存儲和算力上的根本性瓶頸。
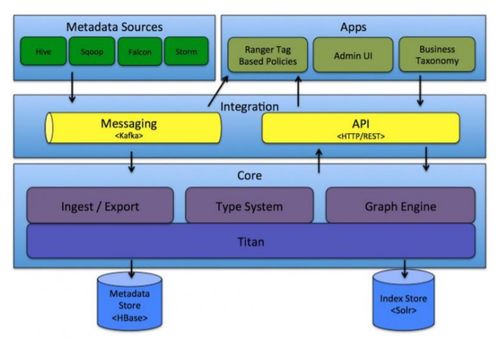
- 分布式計算框架:以Apache Hadoop和Apache Spark為代表。Hadoop的MapReduce編程模型將計算抽象為Map(映射)和Reduce(歸約)兩個階段,適合處理離線批量數(shù)據(jù)。Spark則通過內(nèi)存計算和更豐富的算子(如轉(zhuǎn)換、行動),在迭代計算和流處理上性能更優(yōu),實現(xiàn)了批流一體。
- 分布式存儲系統(tǒng):海量數(shù)據(jù)必須要有可靠的“家”。像HDFS(Hadoop Distributed File System)、Google File System(GFS)以及云時代的對象存儲(如AWS S3),它們將文件切塊并在多個節(jié)點上存儲副本,既提供了巨大的存儲空間,也通過冗余保證了數(shù)據(jù)的高可用性。
- 分布式協(xié)調(diào)與資源管理:管理成百上千臺機器是一個復雜問題。ZooKeeper提供了可靠的分布式協(xié)調(diào)服務(如配置管理、命名服務、分布式鎖)。YARN和Kubernetes則作為集群資源管理器,負責在分布式集群中調(diào)度計算任務,高效利用所有節(jié)點的資源。
構(gòu)建分布式系統(tǒng)帶來了新的挑戰(zhàn):網(wǎng)絡(luò)延遲與故障成為常態(tài)、數(shù)據(jù)一致性難以保證、系統(tǒng)狀態(tài)監(jiān)控和調(diào)試變得異常復雜。CAP理論(一致性、可用性、分區(qū)容錯性不可兼得)指導著我們在設(shè)計時做出權(quán)衡。
技術(shù)棧融合:應對現(xiàn)代數(shù)據(jù)洪流
現(xiàn)代海量數(shù)據(jù)處理架構(gòu),往往是并發(fā)編程與分布式系統(tǒng)技術(shù)的深度融合。
- Lambda/Kappa架構(gòu):在流處理領(lǐng)域,Lambda架構(gòu)同時維護批處理和流處理兩條管道,以平衡延遲與準確性。而Kappa架構(gòu)主張全部用流處理來實現(xiàn),簡化了系統(tǒng)復雜度。Apache Flink作為新一代流處理引擎,以其高吞吐、低延遲和精確的狀態(tài)管理,成為實現(xiàn)這些架構(gòu)的理想選擇。
- 云原生與Serverless:云計算平臺將分布式系統(tǒng)的復雜性進一步封裝。通過容器化、微服務和Serverless計算(如AWS Lambda),開發(fā)者可以更專注于業(yè)務邏輯,而無需深度管理集群。數(shù)據(jù)湖、湖倉一體等概念,也在云上提供了彈性、統(tǒng)一的海量數(shù)據(jù)存儲與分析平臺。
- 并發(fā)與分布式的交織:在一個分布式數(shù)據(jù)處理任務中,每個工作節(jié)點內(nèi)部依然會大量使用并發(fā)編程技術(shù)來最大化自身性能。例如,一個Spark Executor會利用多線程并行執(zhí)行多個Task。
###
從并發(fā)編程到分布式系統(tǒng),海量數(shù)據(jù)處理的演進之路,是一部不斷突破邊界、化解復雜性的歷史。并發(fā)編程是高效利用單機資源的基石,而分布式系統(tǒng)則是應對數(shù)據(jù)規(guī)模無限增長的必由之路。隨著人工智能、物聯(lián)網(wǎng)產(chǎn)生更龐大的數(shù)據(jù)集,處理技術(shù)將繼續(xù)向更智能的自動化調(diào)度、更統(tǒng)一的批流處理、以及更極致的性能與成本優(yōu)化方向發(fā)展。理解從并發(fā)到分布式的技術(shù)全景,是每一位數(shù)據(jù)工程師和系統(tǒng)架構(gòu)師駕馭數(shù)據(jù)洪流的必備素養(yǎng)。